Commencer à utiliser Analytics 2.0
Table des matières
- Connecteur Nuage de Analytique Procore
- Commencer l’installation
- Choisir une méthode de connexion de données
- Se connecter à Power BI Desktop
- Se connecter à SQL Server à l’aide de Python (SSIS)
- Se connecter à SQL Server à l’aide de la bibliothèque Python
- Se connecter à SQL Server à l’aide de Python Spark
- Se connecter à ADLS à l’aide d’Azure Functions
- Se connecter à ADLS à l’aide de Python
- Se connecter à ADLS à l’aide de Spark
- Se connecter à Fabric Lakehouse à l’aide de Data Factory
- Se connecter à Fabric Lakehouse à l’aide de Fabric Notebooks
- Se connecter à SQL Server à l’aide d’Azure Functions
- Se connecter à SQL Server à l’aide de Data Factory
- Se connecter à SQL Server à l’aide de Fabric Notebook
- Se connecter aux Databricks
- Se connecter à Snowflake à l’aide de Python
- Se connecter à Amazon S3 à l’aide de Python
- Construisez votre propre connexion
- Se connecter à BigQuery
- Se connecter à Microsoft Excel à l’aide d’Exponam
Connecteur Nuage de Analytique Procore
Considérations relatives aux partenaires
Vérifier les permissions
Générer des identifiants d’accès aux données
Pour commencer à accéder à vos données Procore, il existe deux options pour générer vos identifiants d’accès aux données : la méthode de connexion directe Databricks ou la méthode Delta Share Token. Le jeton d’accès est une chaîne de chiffres que vous entrez dans votre connecteur de données applicable pour accéder aux données.
Considérations
- Vous devez avoir activé l’outil Analytique au niveau de l’entreprise pour le compte Procore de votre entreprise.
- Par défaut, tous les administrateurs de la compagnie ont un accès de niveau « Admin » à Analytics dans le Répertoire.
- Toute personne disposant d’un accès de niveau « Admin » à l’outil d’analyse peut accorder à des utilisateurs supplémentaires l’accès à l’outil d’analyse.
- Les utilisateurs doivent avoir un accès de niveau « Admin » à l’outil d’analyse pour générer un jeton d’accès.
Étapes
- Connectez-vous à Procore.
- Cliquez sur l’icône Compte et profil dans la zone supérieure droite de la barre de navigation.

- Cliquez sur Paramètres de mon profil.
- Sous Choisissez votre connexion avec Analytics, vous avez deux options pour générer des informations d’identification :
- Databricks se connecte directement OU génère un jeton d’accès personnel avec Delta Share.
- Entrez votre identifiant de partage Databricks pour la méthode de connexion directe Databricks, puis cliquez sur Connecter. Voir Connecter vos données Procore à un espace de travail Databricks en savoir plus.
- Pour la méthode token, sélectionnez Delta Share Token (Jeton de partage Delta).
- Assurez-vous de choisir une date d’expiration.
- Cliquez sur Générer des jetons.
C’est important ! Il est recommandé de copier et de stocker votre jeton pour référence future, car Procore ne stocke pas les jetons pour les utilisateurs. - Vous utiliserez votre jeton au porteur, votre nom de partage, l’URL du serveur de partage Delta et votre version d’identifiants de partage pour commencer à accéder à vos données et à les intégrer.

- Explorez les sections supplémentaires du Guide de démarrage pour connaître les prochaines étapes à suivre pour connecter vos données en fonction de la méthode de connexion de données souhaitée.
Remarque
- Le jeton disparaîtra au bout d’une heure ou il disparaîtra également si vous quittez la page. Pour générer un nouveau jeton, revenez à l’étape 1.
- Il peut s’écouler jusqu’à 24 heures avant que les données ne deviennent visibles.
- Veuillez ne pas régénérer votre jeton pendant cette période de traitement, car cela pourrait causer des problèmes avec votre jeton.
Téléverser des rapports sur Power BI (le cas échéant)
- Accédez à Analytics dans le menu Outils de votre compagnie .
- Accédez à la section Mise en route .
- Sous Fichiers Power BI, sélectionnez et téléchargez les rapports Power BI disponibles.
- Connectez-vous au service Power BI à l’aide de vos informations d’identification de connexion Power BI.
- Créez un espace de travail dans lequel vous souhaitez stocker les rapports analytiques de votre compagnie. Consultez la documentation de support Power BI de Microsoft pour plus d’informations .
Remarques : Des exigences en matière de permis peuvent s’appliquer. - Dans l’espace de travail, cliquez sur Téléverser.
- Cliquez maintenant sur Parcourir.
- Sélectionnez le fichier de rapport à partir de son emplacement sur votre ordinateur et cliquez sur Ouvrir.
- Après avoir téléversé le fichier, cliquez sur Filtre et sélectionnez Modèle sémantique.
- Passez votre curseur sur la ligne portant le nom du rapport et cliquez sur l’icône représentant des points de suspension
 verticaux.
verticaux. - Cliquez sur Paramètres.
- Sur la page des paramètres, cliquez sur Identifiants de la source de données , puis sur Modifier les identifiants.
- Dans la fenêtre « Configurer [Nom du rapport] » qui s'affiche, procédez comme suit :
- Méthode d’authentification : Sélectionnez « Clé ».
- Clé de compte: Saisissez le jeton que vous avez reçu de la page de génération de jetons dans Procore.
- Paramètre de niveau de confidentialité pour cette source de données: sélectionnez le niveau de confidentialité. Nous vous recommandons de sélectionner « Privé » ou « Organisationnel ». Voir la documentation de support Power BI de Microsoft pour plus d'informations sur les niveaux de confidentialité.
- Cliquez sur Connexion.
- Cliquez sur Refresh et procédez comme suit :
- Fuseau horaire: sélectionnez le fuseau horaire que vous souhaitez utiliser pour les actualisations de données planifiées.
- Sous Configurer un programme d’actualisation, basculez le bouton en position ON.
- Fréquence d'actualisation: Sélectionnez « Quotidien ».
- Heure: Cliquez sur Ajouter une autre heure et sélectionnez 7 h 00.
Remarque : Vous pouvez ajouter jusqu’à 8 temps d’actualisation. - Facultatif:
- Cochez la case à cocher « Envoyer des notifications d'échec d'actualisation au propriétaire de l'ensemble de données » pour envoyer des notifications d'échec d'actualisation.
- Saisissez les adresses courriel de tous les autres collègues auxquels vous souhaitez que le système envoie les notifications d'échec d'actualisation.
- Cliquez sur Appliquer.
- Pour vérifier que les paramètres ont été configurés correctement et que les données du rapport s'actualiseront correctement, revenez à la page « Filtrer et sélectionner le modèle sémantique » et procédez comme suit :
- Passez votre curseur sur la ligne portant le nom du rapport et cliquez sur l'icône en forme de flèche circulaire pour actualiser les données manuellement.
- Vérifiez la colonne « Actualisé » pour voir s'il y a un avertissement
 icône.
icône.
- Si aucune icône d’avertissement ne s’affiche, les données du rapport sont actualisées avec succès.
- Si une icône d'avertissement s'affiche, une erreur s'est produite. Cliquez sur l' avertissement pour afficher plus d'informations sur l'erreur.
- Pour supprimer le tableau de bord vide créé automatiquement par le service Power BI, procédez comme suit :
- Passez votre curseur sur la ligne portant le nom du tableau de bord. Cliquez sur les points de suspension
 et cliquez sur Supprimer.
et cliquez sur Supprimer.
- Passez votre curseur sur la ligne portant le nom du tableau de bord. Cliquez sur les points de suspension
- Pour vérifier que le rapport s'affiche correctement, accédez à la page « Tous » ou « Contenu » et cliquez sur le nom du rapport pour afficher le rapport dans le service Power BI.
Conseil
Référencez la colonne « Type » pour vous assurer que vous cliquez sur le rapport au lieu d'un actif différent.
- Répétez les étapes ci-dessus dans Power BI pour chaque fichier de rapport Analytics.
Se connecter à Power BI Desktop
Se connecter à SQL Server à l’aide de Python (SSIS)
Aperçu
L’outil Analytics Nuage Connect Access est une interface de ligne de commande (CLI) qui vous aide à configurer et à gérer les transferts de données de Procore vers MS SQL Server. Il se compose de deux volets principaux :
- user_exp.py (Utilitaire de configuration de la configuration)
- delta_share_to_azure_panda.py (Script de synchronisation des données)
Conditions préalables
- Python et pip installés sur votre système.
- Accès à Procore Delta Share.
- Informations d’identification du compte MS SQL Server.
- Téléchargez le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > options de connexion > SQL Server).
- Installez les dépendances requises : pip install -r requirements.txt.
- Fichier de profil de partage Delta :
- Mettez à jour le jeton et le point de terminaison reçus de l’interface utilisateur Procore dans le fichier template_config.share (qui se trouve dans le contenu téléchargé) et renommez template_config.share en config.share.
- Environnement Python :
- Installez Python 3.9+ et pip sur votre système.
Étapes
- Configuration initiale
- Synchronisation des données
- Configuration du partage Delta
- MS SQL Server Configuration
- SSIS Configuration
Configuration initiale
- Exécutez l’utilitaire de configuration :
python user_exp.py
Cela vous aidera à configurer les éléments suivants :
- Configuration de la source Delta Share
- Configuration de la cible MS SQL Server
- Préférences de planification
Synchronisation des données
Après la configuration, vous avez deux options pour exécuter la synchronisation des données :
- Exécution directe python
delta_share_to_azure_panda.py
OU - Exécution planifiée
S’il est configuré lors de l’installation, le travail s’exécutera automatiquement selon votre planification cron.
Configuration du partage Delta
- Créez un nouveau fichier nommé config.share avec vos informations d’identification Delta Share au format JSON.
{
« shareCredentialsVersion » : 1,
« bearerToken » : « xxxxxxxxxxxxx »,
« endpoint » : « https://nvirginia.nuage. databricks.c... astores/xxxxxx"
}
- Obtenir les champs obligatoires :
Remarque : Ces détails peuvent être obtenus à partir de l’application Web Analytics.- ShareCredentialsVersion : numéro de version (actuellement 1).
- BearerToken : votre jeton d’accès Delta Share.
- Point de terminaison : URL de votre point de terminaison Delta Share.
- Enregistrez le fichier dans un emplacement sûr.
- Lors de la configuration de la source de données, il vous sera demandé de fournir les informations suivantes :
- Liste des tableaux (séparés par des virgules).
- Laisser en blanc pour synchroniser tous les tableaux.
- Exemple : 'table1, t able2, table3'.
- Chemin d’accès à votre fichier « config.share » fichier.
MS SQL Server Configuration
Vous devez fournir les détails MS SQL Server suivants :
- Base de données
- Hébergeur
- mot de passe
- Schéma
- Nom d’utilisateur
SSIS Configuration
- À l’aide de la ligne de commande, accédez au dossier en saisissant « cd <chemin d’accès au dossier> <path to the folder> ».
- Installez les paquets requis à l’aide de 'pip install -r requirements.txt' ou 'python -m pip install -r requirements.txt'.
- Ouvrez SSIS et créez un nouveau projet.
- Dans la boîte à outils SSIS, glisser-déposer l’activité « Exécuter une tâche de processus ».

- Double-cliquez sur « Exécuter la tâche de processus » et accédez à l’onglet Processus.
- Dans 'Exécutable', entrez le chemin d’accès à python.exe dans le dossier d’installation python.
- Dans 'WorkingDirectory', entrez un chemin d’accès au dossier contenant le script que vous souhaitez exécuter (sans nom de fichier de script).
- Dans « Arguments », entrez le nom du script « delta_share_to_azure_panda.py » que vous souhaitez exécuter avec le .py prolonger et sauvegarder.

- Cliquez sur le bouton « Démarrer » dans le volet supérieur :

- Lors de l’exécution de la tâche, la sortie de la console Python s’affiche dans la fenêtre de la console externe.
- Une fois la tâche terminée, elle affichera une coche verte :

Se connecter à SQL Server à l’aide de la bibliothèque Python
Aperçu
Ce guide fournit des directives détaillées sur la configuration et l’utilisation du paquet d’intégration Delta Sharing sur un système d’exploitation Windows afin d’intégrer de manière transparente les données dans vos flux de travail avec Analytics. Le paquet prend en charge plusieurs options d’exécution, vous permettant de choisir la méthode de configuration et d’intégration souhaitée.
Conditions préalables
Assurez-vous d’avoir les éléments suivants avant de continuer :
- Analytique 2.0 SKU
- Fichier de profil de partage Delta :
- Mettez à jour le jeton et le point de terminaison reçus de l’interface utilisateur Procore dans le fichier template_config.share (qui se trouve dans le contenu téléchargé) et renommez template_config.share en config.share.
- Environnement Python :
- Installez Python 3.9+ et pip sur votre système.
Étapes
- Préparer le colis
- Installer les dépendances
- Générer la configuration
- Configurer les tâches cron et l’exécution immédiate
- Exécution et maintenance
Préparer le colis
- Créez un nouveau fichier nommé config.share avec vos informations d’identification Delta Share au format JSON.
{
« shareCredentialsVersion » : 1,
« bearerToken » : « xxxxxxxxxxxxx »,
« endpoint » : « https://nvirginia.nuage. databricks.c... astores/xxxxxx"
}
- Obtenir les champs obligatoires.
Remarque : Ces détails peuvent être obtenus à partir de l’application Web Analytics.- ShareCredentialsVersion : numéro de version (actuellement 1).
- BearerToken : votre jeton d’accès Delta Share.
- Point de terminaison : URL de votre point de terminaison Delta Share.
- Téléchargez et extrayez le paquet.
Remarque : Vous pouvez télécharger le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > Options de connexion > SQL Server). - Décompressez le paquet dans un répertoire de votre choix.
- Copiez le fichier de profil de partage delta *.share dans le répertoire du paquet pour un accès facile.

Installer les dépendances
- Ouvrez un terminal dans le répertoire des paquets.
- Exécutez la commande suivante pour installer les dépendances :
- pip install -r requirements.txt
Générer la configuration
- Générez le fichier config.yaml en exécutant python user_exp.py:
Ce script permet de générer le fichier config.yaml qui contient les informations d’identification et les paramètres nécessaires. - Lors de la configuration de la source de données, il vous sera demandé de fournir les informations suivantes :
- Liste des tableaux (séparés par des virgules).
- Laisser en blanc pour synchroniser tous les tableaux.
Exemple : 'table1, table2, table3'. - Chemin d’accès à votre fichier « config.share » fichier.
- Pour la première fois, vous fournirez vos informations d’identification telles que l’emplacement de configuration de la source Delta Share, les tables, la base de données, l’hôte, etc.
Remarque : Par la suite, vous pouvez réutiliser ou mettre à jour la configuration manuellement ou par l’user_exp.py python en cours d’exécution.
Configurer les tâches cron et l’exécution immédiate (facultatif)
- Décidez s’il faut configurer une tâche cron pour l’exécution automatique.
- Fournissez un échéancier cron :
- Format : * * * * * (minute, heure, jour du mois, mois, jour de la semaine).
- Exemple d’exécution quotidienne à 2 heures du matin : 0 2 * * *
- Pour vérifier les journaux de planification, le fichier 'procore_scheduling.log' sera créé dès que la planification est configurée.
Vous pouvez également vérifier la planification en exécutant la commande du terminal :
Pour Linux et MacOS :
Pour modifier/supprimer - modifiez le cron de l’échéancier en utilisant :
'''bash
EDITOR=nano crontab -e
```
- Après avoir exécuté la commande ci-dessus, vous devriez voir quelque chose de similaire à :
- 2 * * * * /users/your_user/snowflake/venv/bin/python /users/your_user/snowflake/sql_server_python/connection_config.py 2>&1 | while ligne lue ; do echo « $(date) - $line » ; done >> /Users/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- Vous pouvez également ajuster le cron de l’échéancier ou supprimer la ligne entière pour l’empêcher de fonctionner selon l’échéancier.
Pour Windows :
- Vérifiez que la tâche de l’échéancier est créée :
'''Powershell
schtasks /query /tn « ProcoreDeltaShareScheduling » /fo LIST /v
``` - Pour modifier/supprimer - tâche d’échéancier :
Ouvrez le planificateur de tâches :- Appuyez sur Win + R, tapez taskschd.msc, et appuyez sur Entrée.
- Accédez aux tâches planifiées.
- Dans le volet gauche, développez la bibliothèque du planificateur de tâches.
- Recherchez le dossier dans lequel votre tâche est enregistrée (par exemple, la bibliothèque du planificateur de tâches ou un dossier personnalisé).
- Trouvez votre tâche :
- Recherchez le nom de la tâche ProcoreDeltaShareScheduling.
- Cliquez dessus pour afficher ses détails dans le volet inférieur.
- Vérifiez son échéancier :
- Vérifiez l’onglet Déclencheurs pour voir quand la tâche est définie pour s’exécuter.
- Consultez l’onglet Historique pour confirmer les exécutions récentes.
- Pour supprimer la tâche :
- Supprimer la tâche de l’interface graphique.
Question relative à l’exécution immédiate :
- Possibilité d’exécuter un script pour copier les données immédiatement après la configuration.
- Après avoir généré le fichier config.yaml, l’interface de ligne de commande est prête à être exécutée à tout moment indépendamment, en exécutant un script pour copier les données, en fonction de votre package. Voir des exemples ci-dessous :
python delta_share_to_azure_panda.py
OU
python delta_share_to_sql_spark.py
OU
python delta_share_to_azure_dfs_spark.py
Exécution et maintenance
Problèmes courants et solutions
- Configuration de la tâche Cron :
- Assurez-vous que les permissions système sont correctement configurées.
- Vérifiez les journaux système si la tâche échoue à s’exécuter.
- Vérifiez que le script delta_share_to_azure_panda.py dispose des autorisations d’exécution.
- Fichier de configuration :
- Assurez-vous que le fichier config.yaml se trouve dans le même répertoire que le script.
- Sauvegardez le fichier avant d’apporter des modifications.
Soutien
Pour obtenir de l’aide supplémentaire :
- Consultez les journaux de script pour obtenir des messages d’erreur détaillés.
- Vérifiez que le fichier config.yaml ne contient pas d’erreurs de configuration.
- Contactez votre administrateur système pour les problèmes liés aux permissions.
- Contactez le support Procore pour les problèmes liés à l’accès à Delta Share.
- Examiner le journal pour les tables ayant échoué : failed_tables.log.
Remarques
- Sauvegardez toujours vos fichiers de configuration avant d’apporter des modifications.
- Testez de nouvelles configurations dans un environnement hors production pour éviter les interruptions.
Se connecter à SQL Server à l’aide de Python Spark
Aperçu
Ce guide fournit des directives détaillées sur la configuration et l’utilisation du paquet d’intégration Delta Sharing sur un système d’exploitation Windows afin d’intégrer de manière transparente les données dans vos flux de travail avec Analytics. Le paquet prend en charge plusieurs options d’exécution, vous permettant de choisir la méthode de configuration et d’intégration souhaitée.
Conditions préalables
Assurez-vous d’avoir les éléments suivants avant de continuer :
- Analytique 2.0 SKU
- Fichier de profil de partage Delta :
- Mettez à jour le jeton et le point de terminaison reçus de l’interface utilisateur Procore dans le fichier template_config.share (qui se trouve dans le contenu téléchargé) et renommez template_config.share en config.share.
- Environnement Python :
- Installez Python 3.9+ et pip sur votre système.
Étapes
- Préparer le colis
- Installer les dépendances
- Générer la configuration
- Configurer les tâches cron et l’exécution immédiate
- Exécution et maintenance
Préparer le colis
- Créez un nouveau fichier nommé config.share avec vos informations d’identification Delta Share au format JSON.
{
« shareCredentialsVersion » : 1,
« bearerToken » : « xxxxxxxxxxxxx »,
« endpoint » : « https://nvirginia.nuage. databricks.c... astores/xxxxxx"
}
- Obtenir les champs obligatoires.
Remarque : Ces détails peuvent être obtenus à partir de l’application Web Analytics.- ShareCredentialsVersion : numéro de version (actuellement 1).
- BearerToken : votre jeton d’accès Delta Share.
- Point de terminaison : URL de votre point de terminaison Delta Share.
- Téléchargez et extrayez le paquet.
Remarque : Vous pouvez télécharger le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > Options de connexion > SQL Server). - Décompressez le paquet dans un répertoire de votre choix.
- Copiez le fichier de profil de partage delta *.share dans le répertoire du paquet pour un accès facile.
Installer les dépendances
- Ouvrez un terminal dans le répertoire des paquets.
- Exécutez la commande suivante pour installer les dépendances :
- pip install -r requirements.txt
Générer la configuration
- Générez le fichier config.yaml en exécutant python user_exp.py:
Ce script permet de générer le fichier config.yaml qui contient les informations d’identification et les paramètres nécessaires. - Lors de la configuration de la source de données, il vous sera demandé de fournir les informations suivantes :
- Liste des tableaux (séparés par des virgules).
- Laisser en blanc pour synchroniser tous les tableaux.
Exemple : 'table1, table2, table3'. - Chemin d’accès à votre fichier « config.share » fichier.
- Pour la première fois, vous fournirez vos informations d’identification telles que l’emplacement de configuration de la source Delta Share, les tables, la base de données, l’hôte, etc.
Remarque : Par la suite, vous pouvez réutiliser ou mettre à jour la configuration manuellement ou par l’user_exp.py python en cours d’exécution.
Configurer les tâches cron et l’exécution immédiate (facultatif)
- Décidez s’il faut configurer une tâche cron pour l’exécution automatique.
- Fournissez un échéancier cron :
- Format : * * * * * (minute, heure, jour du mois, mois, jour de la semaine).
- Exemple d’exécution quotidienne à 2 heures du matin : 0 2 * * *
- Pour vérifier les journaux de planification, le fichier 'procore_scheduling.log' sera créé dès que la planification est configurée.
Vous pouvez également vérifier la planification en exécutant la commande du terminal :
Pour Linux et MacOS :
Pour modifier/supprimer - modifiez le cron de l’échéancier en utilisant :
'''bash
EDITOR=nano crontab -e
```
- Après avoir exécuté la commande ci-dessus, vous devriez voir quelque chose de similaire à :
- 2 * * * * /users/your_user/snowflake/venv/bin/python /users/your_user/snowflake/sql_server_python/connection_config.py 2>&1 | while ligne lue ; do echo « $(date) - $line » ; done >> /Users/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- Vous pouvez également ajuster le cron de l’échéancier ou supprimer la ligne entière pour l’empêcher de fonctionner selon l’échéancier.
Pour Windows :
- Vérifiez que la tâche de l’échéancier est créée :
'''Powershell
schtasks /query /tn « ProcoreDeltaShareScheduling » /fo LIST /v
``` - Pour modifier/supprimer - tâche d’échéancier :
Ouvrez le planificateur de tâches :- Appuyez sur Win + R, tapez taskschd.msc, et appuyez sur Entrée.
- Accédez aux tâches planifiées.
- Dans le volet gauche, développez la bibliothèque du planificateur de tâches.
- Recherchez le dossier dans lequel votre tâche est enregistrée (par exemple, la bibliothèque du planificateur de tâches ou un dossier personnalisé).
- Trouvez votre tâche :
- Recherchez le nom de la tâche ProcoreDeltaShareScheduling.
- Cliquez dessus pour afficher ses détails dans le volet inférieur.
- Vérifiez son échéancier :
- Vérifiez l’onglet Déclencheurs pour voir quand la tâche est définie pour s’exécuter.
- Consultez l’onglet Historique pour confirmer les exécutions récentes.
- Pour supprimer la tâche :
- Supprimer la tâche de l’interface graphique.
Question relative à l’exécution immédiate :
- Possibilité d’exécuter un script pour copier les données immédiatement après la configuration.
- Après avoir généré le fichier config.yaml, l’interface de ligne de commande est prête à être exécutée à tout moment indépendamment, en exécutant un script pour copier les données, en fonction de votre package. Voir des exemples ci-dessous :
python delta_share_to_azure_panda.py
OU
python delta_share_to_sql_spark.py
OU
python delta_share_to_azure_dfs_spark.py
Exécution et maintenance
Problèmes courants et solutions
- Configuration de la tâche Cron :
- Assurez-vous que les permissions système sont correctement configurées.
- Vérifiez les journaux système si la tâche échoue à s’exécuter.
- Vérifiez que le script delta_share_to_azure_panda.py dispose des autorisations d’exécution.
- Fichier de configuration :
- Assurez-vous que le fichier config.yaml se trouve dans le même répertoire que le script.
- Sauvegardez le fichier avant d’apporter des modifications.
Soutien
Pour obtenir de l’aide supplémentaire :
- Consultez les journaux de script pour obtenir des messages d’erreur détaillés.
- Vérifiez que le fichier config.yaml ne contient pas d’erreurs de configuration.
- Contactez votre administrateur système pour les problèmes liés aux permissions.
- Contactez le support Procore pour les problèmes liés à l’accès à Delta Share.
- Examiner le journal pour les tables ayant échoué : failed_tables.log.
Remarques
- Sauvegardez toujours vos fichiers de configuration avant d’apporter des modifications.
- Testez de nouvelles configurations dans un environnement hors production pour éviter les interruptions.
Se connecter à ADLS à l’aide d’Azure Functions
Se connecter à ADLS à l’aide de Python
Aperçu
Ce guide fournit des directives détaillées sur la configuration et l’utilisation du paquet d’intégration Delta Sharing sur un système d’exploitation Windows afin d’intégrer de manière transparente les données dans vos flux de travail avec Analytics. Le paquet prend en charge plusieurs options d’exécution, vous permettant de choisir la méthode de configuration et d’intégration souhaitée.
Conditions préalables
Assurez-vous d’avoir les éléments suivants avant de procéder :
- Analytique 2.0 SKU
- Fichier de profil de partage Delta :
- Mettez à jour le jeton et le point de terminaison reçus de l’interface utilisateur Procore dans le fichier template_config.share (qui se trouve dans le contenu téléchargé) et renommez template_config.share en config.share.
- Environnement Python :
- Installez Python 3.9+ et pip sur votre système.
Étapes
- Préparer le paquet
- Installer des dépendances
- Générer la configuration
- Configurer les tâches Cron et l’exécution immédiate
- Exécution et maintenance
Préparer le paquet
- Créez un nouveau fichier nommé config.share avec vos informations d’identification Delta Share en format JSON.
{
« shareCredentialsVersion » : 1,
« bearerToken » : « xxxxxxxxxxxxx »,
« endpoint » : « https://nvirginia.nuage. databricks.c... astores/xxxxxx"
}
- Obtenir les champs obligatoires.
Remarque : Ces détails peuvent être obtenus à partir de l’application Web Analytics.- ShareCredentialsVersion : Numéro de version (actuellement 1).
- BearerToken : Votre jeton d’accès Delta Share.
- Point de terminaison : URL de votre point de terminaison Delta Share.
- Téléchargez et extrayez le paquet.
Remarque : Vous pouvez télécharger le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > Options de connexion > Azure). - Décompressez le paquet dans un répertoire de votre choix.
- Copiez le fichier de profil de partage delta *.share dans le répertoire du paquet pour un accès facile.
Installer des dépendances
- Ouvrez un terminal dans le répertoire du paquet.
- Exécutez la commande suivante pour installer les dépendances :
- pip install -r requirements.txt
Générer la configuration
- Générez le fichier config.yaml en exécutant python user_exp.py:
Ce script aide à générer le fichier config.yaml qui contient les informations d’identification et les paramètres nécessaires. - Lors de la configuration de la source de données, il vous sera demandé de fournir :
- Liste des tableaux (séparés par des virgules).
- Laisser en blanc pour synchroniser tous les tableaux.
Exemple : «tableau1, table2, table3». - Chemin vers votre 'config.share' fichier.
- Pour la première fois, vous fournirez vos informations d’identification telles que l’emplacement de configuration de la source Delta Share, les tables, la base de données, l’hôte, etc.
Remarque : Ensuite, vous pouvez réutiliser ou mettre à jour la configuration manuellement ou par le user_exp.py python en cours d’exécution.
Configurer les tâches Cron et l’exécution immédiate (facultatif)
- Décidez de configurer un travail cron pour l’exécution automatique.
- Fournissez un échéancier cron :
- Format : * * * * * (minute, heure, jour du mois, mois, jour de la semaine).
- Exemple d’exécution quotidienne à 2 h : 0 2 * * *
- Pour vérifier les registres d’échéancier, le fichier « procore_scheduling.log » sera créé dès que l’échéancier sera configuré.
Vous pouvez également vérifier l’ordonnancement en exécutant la commande terminal :
Pour Linux et MacOs :
Pour modifier/supprimer - modifiez le cron d’échéancier en utilisant :
« Bash »
EDITOR=nano crontab -e
```
- Après avoir exécuté la commande ci-dessus, vous devriez voir quelque chose de similaire à :
- 2 * * * * /Utilisateurs/your_user/flocon de neige/venv/bin/python /Utilisateurs/your_user/flocon de neige/sql_server_python/connection_config.py 2>&1 | tout en lisant la ligne; do echo « $(date) - $line »; fait >> /Users/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- Vous pouvez également ajuster le cron de l’échéancier ou supprimer toute la ligne pour l’arrêter selon l’échéancier.
Pour Windows :
- Vérifiez que la tâche de l’échéancier est créée :
'''PowerShell
schtasks /query /tn « ProcoreDeltaShareScheduling » /fo LIST /v
``` - Pour modifier/supprimer - tâche d’échéancier :
Ouvrez l’échéancier de tâches :- Appuyez sur Win + R, tapez taskschd.msc, et appuyez sur Entrée.
- Accédez aux tâches planifiées.
- Dans le volet gauche, développez la bibliothèque du planificateur de tâches.
- Recherchez le dossier dans lequel votre tâche est enregistrée (par exemple, bibliothèque de planification de tâches ou un dossier personnalisé).
- Trouvez votre tâche :
- Recherchez le nom de la tâche ProcoreDeltaShareScheduling.
- Cliquez dessus pour afficher ses détails dans le volet du bas.
- Vérifiez son échéancier :
- Vérifiez l’onglet Déclencheurs pour voir quand la tâche est configurée pour s’exécuter.
- Consultez l’onglet Historique pour confirmer les exécutions récentes.
- Pour supprimer la tâche :
- Supprimer la tâche de l’interface graphique.
Question d’exécution immédiate :
- Option pour exécuter un script pour copier les données immédiatement après la configuration.
- Après avoir généré le fichier config.yaml, l’interface de ligne de commande est prête à être exécutée à tout moment indépendamment, en exécutant un script pour copier les données, selon votre paquet. Voir des exemples ci-dessous :
Python delta_share_to_azure_panda.py
OU
Python delta_share_to_sql_spark.py
OU
Python delta_share_to_azure_dfs_spark.py
Exécution et maintenance
Problèmes courants et solutions
- Configuration du projet Cron :
- Assurez-vous que les permissions système sont correctement configurées.
- Vérifiez les registres système si la tâche ne parvient pas à s’exécuter.
- Vérifiez que le script delta_share_to_azure_panda.py dispose des permissions d’exécution.
- Fichier de configuration :
- Assurez-vous que le fichier config.yaml se trouve dans le même répertoire que le script.
- Sauvegardez le fichier avant d’apporter des modifications.
Soutien
Pour obtenir de l’aide supplémentaire :
- Consultez les registres de script pour obtenir des messages d’erreur détaillés.
- Vérifiez que le fichier config.yaml n’a pas de mauvaises configurations.
- Contactez votre administrateur système pour les problèmes liés aux permissions.
- Contactez le support Procore pour les problèmes liés à l’accès Delta Share.
- Consulter le registre des tables ayant échoué : failed_tables.log.
Remarques
- Sauvegardez toujours vos fichiers de configuration avant d’apporter des modifications.
- Testez de nouvelles configurations dans un environnement hors production pour éviter les perturbations.
Se connecter à ADLS à l’aide de Spark
Aperçu
Ce guide fournit des directives détaillées sur la configuration et l’utilisation du paquet d’intégration Delta Sharing sur un système d’exploitation Windows afin d’intégrer de manière transparente les données dans vos flux de travail avec Analytics. Le paquet prend en charge plusieurs options d’exécution, vous permettant de choisir la méthode de configuration et d’intégration souhaitée.
Conditions préalables
Assurez-vous d’avoir les éléments suivants avant de procéder :
- Analytique 2.0 SKU
- Fichier de profil de partage Delta :
- Mettez à jour le jeton et le point de terminaison reçus de l’interface utilisateur Procore dans le fichier template_config.share (qui se trouve dans le contenu téléchargé) et renommez template_config.share en config.share.
- Environnement Python :
- Installez Python 3.9+ et pip sur votre système.
Étapes
- Préparer le paquet
- Installer des dépendances
- Générer la configuration
- Configurer les tâches Cron et l’exécution immédiate
- Exécution et maintenance
Préparer le paquet
- Créez un nouveau fichier nommé config.share avec vos informations d’identification Delta Share en format JSON.
{
« shareCredentialsVersion » : 1,
« bearerToken » : « xxxxxxxxxxxxx »,
« endpoint » : « https://nvirginia.nuage. databricks.c... astores/xxxxxx"
}
- Obtenir les champs obligatoires.
Remarque : Ces détails peuvent être obtenus à partir de l’application Web Analytics.- ShareCredentialsVersion : Numéro de version (actuellement 1).
- BearerToken : Votre jeton d’accès Delta Share.
- Point de terminaison : URL de votre point de terminaison Delta Share.
- Téléchargez et extrayez le paquet.
Remarque : Vous pouvez télécharger le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > Options de connexion > Azure). - Décompressez le paquet dans un répertoire de votre choix.
- Copiez le fichier de profil de partage delta *.share dans le répertoire du paquet pour un accès facile.
Installer des dépendances
- Ouvrez un terminal dans le répertoire du paquet.
- Exécutez la commande suivante pour installer les dépendances :
- pip install -r requirements.txt
Générer la configuration
- Générez le fichier config.yaml en exécutant python user_exp.py:
Ce script aide à générer le fichier config.yaml qui contient les informations d’identification et les paramètres nécessaires. - Lors de la configuration de la source de données, il vous sera demandé de fournir :
- Liste des tableaux (séparés par des virgules).
- Laisser en blanc pour synchroniser tous les tableaux.
Exemple : «tableau1, table2, table3». - Chemin vers votre 'config.share' fichier.
- Pour la première fois, vous fournirez vos informations d’identification telles que l’emplacement de configuration de la source Delta Share, les tables, la base de données, l’hôte, etc.
Remarque : Ensuite, vous pouvez réutiliser ou mettre à jour la configuration manuellement ou par le user_exp.py python en cours d’exécution.
Configurer les tâches Cron et l’exécution immédiate (facultatif)
- Décidez de configurer un travail cron pour l’exécution automatique.
- Fournissez un échéancier cron :
- Format : * * * * * (minute, heure, jour du mois, mois, jour de la semaine).
- Exemple d’exécution quotidienne à 2 h : 0 2 * * *
- Pour vérifier les registres d’échéancier, le fichier « procore_scheduling.log » sera créé dès que l’échéancier sera configuré.
Vous pouvez également vérifier l’ordonnancement en exécutant la commande terminal :
Pour Linux et MacOs :
Pour modifier/supprimer - modifiez le cron d’échéancier en utilisant :
« Bash »
EDITOR=nano crontab -e
```
- Après avoir exécuté la commande ci-dessus, vous devriez voir quelque chose de similaire à :
- 2 * * * * /Utilisateurs/your_user/flocon de neige/venv/bin/python /Utilisateurs/your_user/flocon de neige/sql_server_python/connection_config.py 2>&1 | tout en lisant la ligne; do echo « $(date) - $line »; fait >> /Users/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- Vous pouvez également ajuster le cron de l’échéancier ou supprimer toute la ligne pour l’arrêter selon l’échéancier.
Pour Windows :
- Vérifiez que la tâche de l’échéancier est créée :
'''PowerShell
schtasks /query /tn « ProcoreDeltaShareScheduling » /fo LIST /v
``` - Pour modifier/supprimer - tâche d’échéancier :
Ouvrez l’échéancier de tâches :- Appuyez sur Win + R, tapez taskschd.msc, et appuyez sur Entrée.
- Accédez aux tâches planifiées.
- Dans le volet gauche, développez la bibliothèque du planificateur de tâches.
- Recherchez le dossier dans lequel votre tâche est enregistrée (par exemple, bibliothèque de planification de tâches ou un dossier personnalisé).
- Trouvez votre tâche :
- Recherchez le nom de la tâche ProcoreDeltaShareScheduling.
- Cliquez dessus pour afficher ses détails dans le volet du bas.
- Vérifiez son échéancier :
- Vérifiez l’onglet Déclencheurs pour voir quand la tâche est configurée pour s’exécuter.
- Consultez l’onglet Historique pour confirmer les exécutions récentes.
- Pour supprimer la tâche :
- Supprimer la tâche de l’interface graphique.
Question d’exécution immédiate :
- Option pour exécuter un script pour copier les données immédiatement après la configuration.
- Après avoir généré le fichier config.yaml, l’interface de ligne de commande est prête à être exécutée à tout moment indépendamment, en exécutant un script pour copier les données, selon votre paquet. Voir des exemples ci-dessous :
Python delta_share_to_azure_panda.py
OU
Python delta_share_to_sql_spark.py
OU
Python delta_share_to_azure_dfs_spark.py
Exécution et maintenance
Problèmes courants et solutions
- Configuration du projet Cron :
- Assurez-vous que les permissions système sont correctement configurées.
- Vérifiez les registres système si la tâche ne parvient pas à s’exécuter.
- Vérifiez que le script delta_share_to_azure_panda.py dispose des permissions d’exécution.
- Fichier de configuration :
- Assurez-vous que le fichier config.yaml se trouve dans le même répertoire que le script.
- Sauvegardez le fichier avant d’apporter des modifications.
Soutien
Pour obtenir de l’aide supplémentaire :
- Consultez les registres de script pour obtenir des messages d’erreur détaillés.
- Vérifiez que le fichier config.yaml n’a pas de mauvaises configurations.
- Contactez votre administrateur système pour les problèmes liés aux permissions.
- Contactez le support Procore pour les problèmes liés à l’accès Delta Share.
- Consulter le registre des tables ayant échoué : failed_tables.log.
Remarques
- Sauvegardez toujours vos fichiers de configuration avant d’apporter des modifications.
- Testez de nouvelles configurations dans un environnement hors production pour éviter les perturbations.
Se connecter à Fabric Lakehouse à l’aide de Data Factory
Aperçu
L’intégration du partage Delta avec Microsoft Fabric Data Factory permet un accès et un traitement transparents aux tables Delta partagées pour vos flux de travail d’analyse avec Analytics 2.0. Delta Sharing, un protocole ouvert pour la collaboration sécurisée des données, garantit que les organisations peuvent partager des données sans doublon.
Conditions préalables
- Analytique 2.0 SKU
- Informations d’identification de partage Delta:
- Obtenez le fichier d’informations d’identification Delta Sharing share.json (ou équivalent) auprès de votre fournisseur de données.
- Ce fichier doit comprendre :
- URL du point de terminaison : URL du serveur de partage Delta.
- Jeton au porteur : Utilisé pour un accès sécurisé aux données.
- Configuration de Microsoft Fabric :
- Un compte de locataire Microsoft Fabric avec un abonnement actif.
- Accès à un espace de travail compatible avec Microsoft Fabric.
Étapes
- Passer à l’expérience Data Factory
- Configurer le flux de données
- Effectuer des transformations de données
- Validation et suivi
Passer à l’expérience Data Factory
- Accédez à votre espace de travail Microsoft Fabric.

- Sélectionnez Nouveau, puis choisissez Dataflow Gen2.

Configurer le flux de données
- Accédez à l’éditeur de flux de données.
- Cliquez sur Obtenir des données et sélectionnez Plus.
- Sous Nouvelle source, sélectionnez Delta Sharing Other comme source de données.
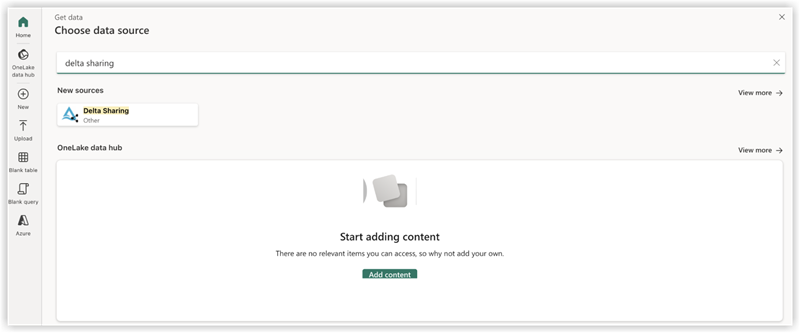
- Saisissez les informations suivantes :
- URL: à partir de votre fichier de configuration Delta Sharing.
- Jeton de porteur: Trouvé dans votre fichier config.share.

- Cliquez sur Suivant et sélectionnez les tables souhaitées.
- Cliquez sur Créer pour terminer la configuration.
Effectuer des transformations de données
Après avoir configuré le flux de données, vous pouvez maintenant appliquer des transformations aux données Delta partagées. Choisissez votre option Delta Sharing Data dans la liste ci-dessous :
- Ajouter une destination de données
- Créer/ouvrir Lakehouse
Ajouter une destination de données
- Accédez à Data Factory.
- Cliquez sur Ajouter une destination de données.
- Sélectionnez Lakehouse comme cible et cliquez sur Suivant.
- Choisissez votre cible de destination et confirmez en cliquant sur Suivant.
Créer-Ouvrir Lakehouse
- Créez/ouvrez votreLakehouse et cliquez sur Obtenir des données.
- Sélectionnez Nouveau flux de données de 2e génération.
- Cliquez sur Obtenir des données, puis sur Plus et recherchez Partage Delta.
- Entrez le jeton du support d’URL à partir de votre fichier config.share, puis sélectionnez Next.
- Choisissez vos données/table(s) à télécharger et cliquez sur Suivant.
- Après ces manipulations, vous devriez avoir toutes les données sélectionnées dans votre Fabric Lakehouse.
Validation et suivi
Testez vos pipelines et flux de données pour garantir une exécution fluide. Utiliser des outils de surveillance au sein des données
Usine pour suivre les progrès et les journaux pour chaque activité.
Se connecter à Fabric Lakehouse à l’aide de Fabric Notebooks
Aperçu
L’utilisation de Data Factory dans Microsoft Fabric avec Delta Sharing permet une intégration et un traitement transparents des tables Delta partagées dans le cadre de vos flux de travail d’analyse avec Analytics 2.0. Delta Sharing est un protocole ouvert pour le partage sécurisé des données, permettant la collaboration entre les organisations sans dupliquer les données.
Ce guide vous guide tout au long des étapes de configuration et d’utilisation de Data Factory dans Fabric avec Delta Sharing, à l’aide de blocs-notes pour le traitement et l’exportation de données vers un Lakehouse.
Conditions préalables
- Analytique 2.0 SKU
- Informations d’identification de partage Delta :
- Accès aux informations d’identification Delta Sharing fournies par un fournisseur de données.
- Un fichier de profil de partage (config.share) contenant :
- URL du point de terminaison (URL du serveur de partage Delta).
- Jeton d’accès (jeton du porteur pour un accès sécurisé aux données).
- Créez votre fichier config.yaml avec des informations d’identification spécifiques à l’aide du modèle ci-dessous :
{
"shareCredentialsVersion": 1,
"endpoint": "your-delta-sharing-server-url",
"bearerToken": "your-master-token"
}
- Environnement Microsoft Fabric :
- Un compte de locataire Microsoft Fabric avec un abonnement actif.
- Un espace de travail compatible avec Fabric.
- Paquets et scripts :
- Téléchargez le paquet fabric-lakehouse. Le répertoire doit comprendre :
- ds_to_lakehouse.py : Code du bloc-notes.
- readme.md : Directives.
Remarque : Vous pouvez télécharger le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > Options de connexion > Azure).
- Téléchargez le paquet fabric-lakehouse. Le répertoire doit comprendre :
Étapes
Configurer la configuration
- Créez le fichier config.yaml et définissez la configuration dans la structure suivante
source_config :
config_path : chemin/vers/votre/delta-sharing-credentials-file.share
tables : # Facultatif - Laisser vide pour traiter toutes les tables
- table_name1
- table_name2
target_config :
lakehouse_path : chemin/vers/votre/tissu/maison-du-lac/tables/ # chemin d’accès à la maison du lac de tissu
Configurez votre maison au bord du lac
- Ouvrez votre espace de travail Microsoft Fabric.
- Accédez à votre Lakehouse et cliquez sur Ouvrir le bloc-notes, puis sur Nouveau bloc-notes.
- Si vous ne connaissez pas la valeur dans config.yaml#lakehouse_path, Vous pouvez le copier à partir de l’écran.
- Cliquez sur les points de suspension à côté de Fichiers, puis sélectionnez Copier le chemin ABFS:



3. Copiez le code de ds_to_lakehouse.py et collez-le dans la fenêtre du bloc-notes (Pyspark Python) :

L’étape suivante consiste à télécharger vos propres fichiers config.yaml et config.share dans le dossier Resources de Lakehouse. Vous pouvez créer votre propre répertoire ou utiliser un répertoire intégré (déjà créé pour les ressources par Lakehouse) :


L’exemple ci-dessous montre un répertoire intégré standard pour un fichier config.yaml .
Remarque : Assurez-vous de téléverser les deux fichiers au même niveau et pour la propriété config_path:

4. Vérifiez le code du bloc-notes, lignes 170-175.
L’exemple ci-dessous montre les modifications de ligne nécessaires :
config_path = « ./env/config.yaml »
à
config_path = « ./builtin/config.yaml»
Étant donné que les fichiers se trouvent dans un dossier intégré et non dans un environnement personnalisé, assurez-vous de surveiller votre propre structure des fichiers. Vous pouvez les charger dans différents dossiers, mais dans ce cas, mettez à jour le code du bloc-notes pour trouver correctement le fichier config.yaml .

5. Cliquez sur Exécuter la cellule :

Validation
- Une fois le travail terminé, vérifiez que les données ont bien été copiées dans votre Lakehouse.
- Vérifiez les tables spécifiées et assurez-vous que les données correspondent aux tables Delta partagées.
- Attendez que le travail soit terminé, il devrait copier toutes les données.
Se connecter à SQL Server à l’aide d’Azure Functions
Se connecter à SQL Server à l’aide de Data Factory
Vue d’ensemble
Ce document fournit des instructions pas à pas pour la configuration d’un pipeline de données dans Microsoft Fabric afin de transférer des données de Delta Share vers un entrepôt SQL. Cette configuration permet une intégration transparente des données entre les sources Delta Lake et les destinations SQL.
Conditions préalables
- Compte Microsoft Fabric actif avec les autorisations appropriées.
- Informations d’identification Delta Share.
- Informations d’identification de l’entrepôt SQL.
- Accès au flux de données Gen2 dans Fabric.
Étapes
- Flux de données d’accès Gen2
- Configurer les données La source
- Configurer la connexion Delta Share
- Configurer la destination des données
- Finaliser et déployer
- Vérification
- Dépannage
Flux de données d’accès Gen2
- Connectez-vous à votre compte Microsoft Fabric.
- Accédez à l’espace de travail.
- Sélectionnez « Flux de données Gen2 » parmi les options disponibles.
Configurer la source de données
- Cliquez sur « Données provenant d’une autre source » pour commencer la configuration.
- À partir de l’écran Obtenir des données, procédez comme suit :
- Localisez la barre de recherche intitulée « Choisir une source de données ».
- Tapez « partage delta » dans le champ de recherche.
- Sélectionnez Partage Delta dans les résultats.
Configurer la connexion Delta Share
- Saisissez vos informations d’identification Delta Share lorsque vous y êtes invité.
- Assurez-vous que tous les champs obligatoires sont remplis avec exactitude.
- Validez la connexion si possible.
- Cliquez sur « Suivant » pour continuer.
- Consultez la liste des tableaux disponibles :
- Toutes les tables auxquelles vous avez accès seront affichées.
- Sélectionnez les tables souhaitées pour le transfert.
Configurer la destination des données
- Cliquez sur « Ajouter une destination de données ».
- Sélectionnez « Entrepôt SQL » comme destination.
- Entrez les informations d’identification SQL :
- Détails du serveur.
- Informations d’authentification.
- Spécifications de la base de données.
- Vérifiez les paramètres de connexion.
Finaliser et déployer
- Passez en revue toutes les configurations.
- Cliquez sur « Publier » pour déployer le flux de données.
- Attendez le message de confirmation.
Vérification
- Accédez à votre entrepôt SQL.
- Vérifiez que les données sont disponibles et correctement structurées.
- Exécutez des requêtes de test pour garantir l’intégrité des données.
Dépannage
Problèmes courants et solutions :
- Échecs de connexion : vérifiez les informations d’identification et la connectivité réseau.
- Tables manquantes : Cochez les autorisations Delta Share.
- Problèmes de performances : examinez les paramètres d’allocation et d’optimisation des ressources.
Se connecter à SQL Server à l’aide de Fabric Notebook
Aperçu
L’utilisation de Data Factory dans Microsoft Fabric avec Delta Sharing permet une intégration et un traitement transparents des tables Delta partagées dans le cadre de vos flux de travail d’analyse avec Analytics 2.0. Delta Sharing est un protocole ouvert pour le partage sécurisé des données, permettant la collaboration entre les organisations sans dupliquer les données.
Ce guide vous guide tout au long des étapes de configuration et d’utilisation de Data Factory dans Fabric avec Delta Sharing, à l’aide de blocs-notes pour le traitement et l’exportation de données vers un Lakehouse.
Conditions préalables
- Analytique 2.0 SKU
- Informations d’identification de partage Delta :
- Accès aux informations d’identification Delta Sharing fournies par un fournisseur de données.
- Un fichier de profil de partage (config.share) contenant :
- URL du point de terminaison (URL du serveur de partage Delta).
- Jeton d’accès (jeton du porteur pour un accès sécurisé aux données).
- Créez votre fichier config.yaml avec des informations d’identification spécifiques à l’aide du modèle ci-dessous :
{
"shareCredentialsVersion": 1,
"endpoint": "your-delta-sharing-server-url",
"bearerToken": "your-master-token"
}
- Environnement Microsoft Fabric :
- Un compte de locataire Microsoft Fabric avec un abonnement actif.
- Un espace de travail compatible avec Fabric.
- Paquets et scripts :
- Téléchargez le paquet fabric-lakehouse. Le répertoire doit comprendre :
- ds_to_lakehouse.py : Code du bloc-notes.
- readme.md : Directives.
Remarque : Vous pouvez télécharger le paquet compressé à partir de l’outil d’analyse au niveau de la compagnie (via Analytics > Mise en route > Options de connexion > Azure).
- Téléchargez le paquet fabric-lakehouse. Le répertoire doit comprendre :
Étapes
Configurer la configuration
- Créez le fichier config.yaml et définissez la configuration dans la structure suivante
source_config :
config_path : chemin/vers/votre/delta-sharing-credentials-file.share
tables : # Facultatif - Laisser vide pour traiter toutes les tables
- table_name1
- table_name2
target_config :
lakehouse_path : chemin/vers/votre/tissu/maison-du-lac/tables/ # chemin d’accès à la maison du lac de tissu
Configurez votre maison au bord du lac
- Ouvrez votre espace de travail Microsoft Fabric.
- Accédez à votre Lakehouse et cliquez sur Ouvrir le bloc-notes, puis sur Nouveau bloc-notes.
- Si vous ne connaissez pas la valeur dans config.yaml#lakehouse_path, Vous pouvez le copier à partir de l’écran.
- Cliquez sur les points de suspension à côté de Fichiers, puis sélectionnez Copier le chemin ABFS:
3. Copiez le code de ds_to_lakehouse.py et collez-le dans la fenêtre du bloc-notes (Pyspark Python) :
L’étape suivante consiste à télécharger vos propres fichiers config.yaml et config.share dans le dossier Resources de Lakehouse. Vous pouvez créer votre propre répertoire ou utiliser un répertoire intégré (déjà créé pour les ressources par Lakehouse) :
L’exemple ci-dessous montre un répertoire intégré standard pour un fichier config.yaml .
Remarque : Assurez-vous de téléverser les deux fichiers au même niveau et pour la propriété config_path:
4. Vérifiez le code du bloc-notes, lignes 170-175.
L’exemple ci-dessous montre les modifications de ligne nécessaires :
config_path = « ./env/config.yaml »
à
config_path = « ./builtin/config.yaml»
Étant donné que les fichiers se trouvent dans un dossier intégré et non dans un environnement personnalisé, assurez-vous de surveiller votre propre structure des fichiers. Vous pouvez les charger dans différents dossiers, mais dans ce cas, mettez à jour le code du bloc-notes pour trouver correctement le fichier config.yaml .
5. Cliquez sur Exécuter la cellule :
Validation
- Une fois le travail terminé, vérifiez que les données ont bien été copiées dans votre Lakehouse.
- Vérifiez les tables spécifiées et assurez-vous que les données correspondent aux tables Delta partagées.
- Attendez que le travail soit terminé, il devrait copier toutes les données.
Se connecter aux Databricks
Remarque
Cette méthode de connexion est généralement utilisée par les professionnels de la data.- Connectez-vous à votre environnement Databricks.
- Accédez à la section Catalogue .
- Sélectionnez Partage Delta dans le menu supérieur.
- Sélectionnez Partagé avec moi.
- Copiez l’identifiant de partage qui vous a été fourni.

- Dans Procore, cliquez sur l’icône Compte et profil dans la zone supérieure droite de la barre de navigation.
- Cliquez sur Paramètres de mon profil.
- Cliquez sur l’onglet Analyse.
- Entrez votre identifiant de partage Databricks.
- Cliquez sur Connecter.
Remarque : Une fois l’identifiant de partage ajouté au système de Procore, la connexion Procore Databricks apparaîtra dans l’onglet Partagé avec moi sous Fournisseurs dans votre environnement Databricks. Cela peut prendre jusqu’à 24 heures pour voir les données.

- Lorsque votre connexion Procore Databricks devient visible dans l’onglet Partagé avec moi , sélectionnez l’indentificateur Procore et cliquez sur Créer un catalogue.
- Entrez votre nom préféré pour le catalogue partagé et cliquez sur Créer.

- Votre catalogue et vos tableaux partagés s’afficheront désormais sous le nom fourni dans le Explorateur de catalogue.

Remarque : Veuillez contacter le support Procore si vous avez des questions ou avez besoin d’aide.
Se connecter à Snowflake à l’aide de Python
Se connecter à Amazon S3 à l’aide de Python
Construisez votre propre connexion
Se connecter à BigQuery
Se connecter à Microsoft Excel à l’aide d’Exponam
Aperçu
Ce guide fournit des instructions étape par étape pour importer des données Analytics de Delta Share directement dans Microsoft Excel à l’aide du complément Exponam.Connect.
L’utilisation de cette méthode vous permet de :
-
Accédez à vos données Procore directement dans Excel sans télécharger manuellement les fichiers CSV.
-
Filtrez et sélectionnez des colonnes spécifiques avant l’importation, en vous assurant de ne charger que les données dont vous avez besoin.
-
Travaillez avec de grands ensembles de données qui pourraient autrement être trop lents à traiter.
Conditions préalables
-
Identifiants Delta Share. Accès au fichier config.share contenant les informations d’identification Delta Sharing.
-
Licence :
-
Exponam.Connect Gratuit: Limité à l’importation de 100 lignes de données.
-
Exponam.Connect Pro: Requis pour importer des ensembles de données plus volumineux (jusqu’à 1 million + de lignes).
-
Installer le module complémentaire Exponam
-
Téléchargez le fichier Exponam.Connectinstallateur pour votre système d’exploitation (Windows ou Mac).
-
Exécutez le fichier d’installation et suivez les invites à l’écran.
-
Une fois l’installation terminée, lancez Microsoft Excel et ouvrez un nouveau classeur.
Initialiser la connexion de partage Delta
-
Dans Microsoft Excel, accédez à l’onglet Exponam Pro .
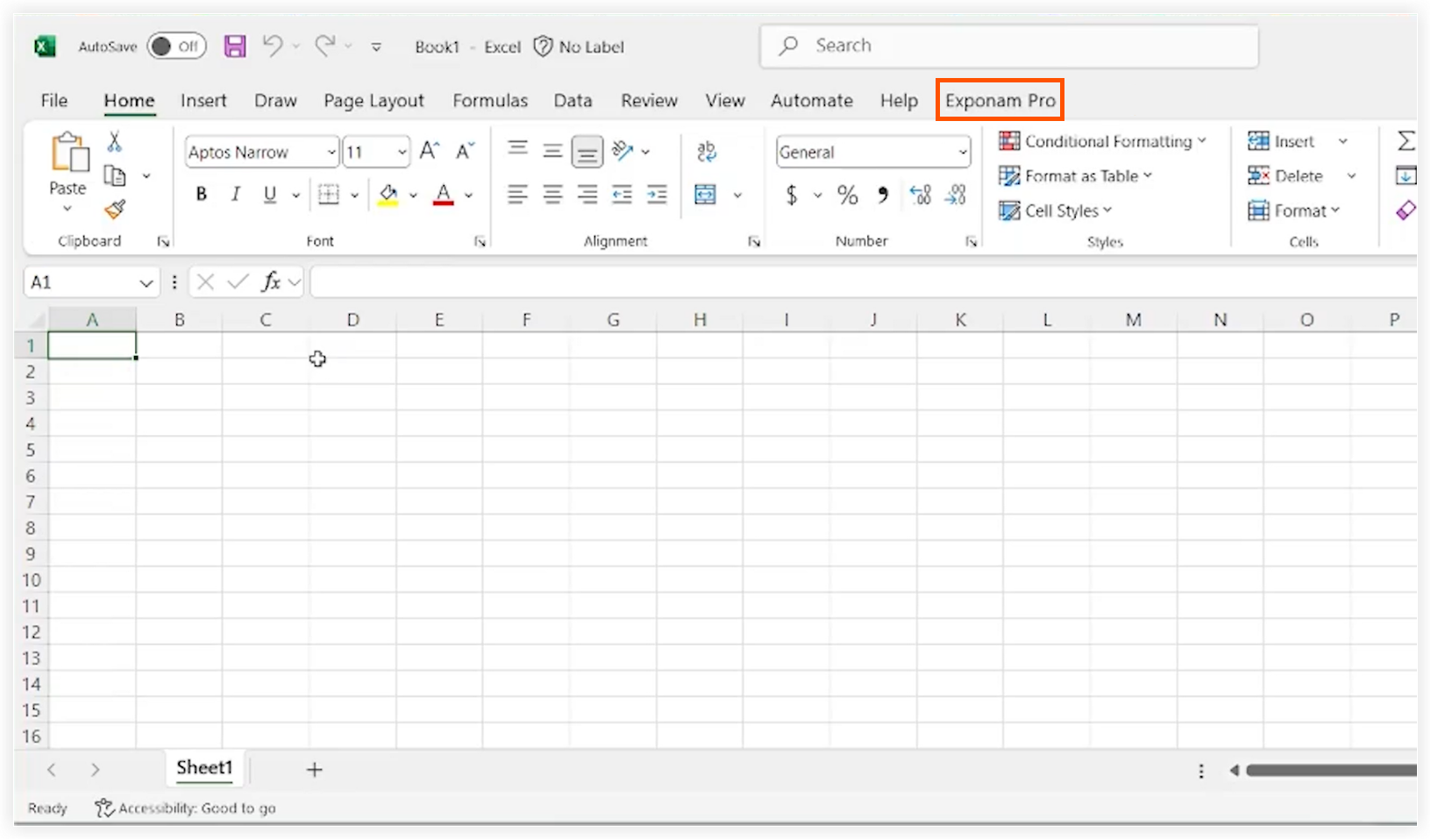
-
Cliquez sur Importer des données.
-
Cliquez sur l’icône Delta Share .
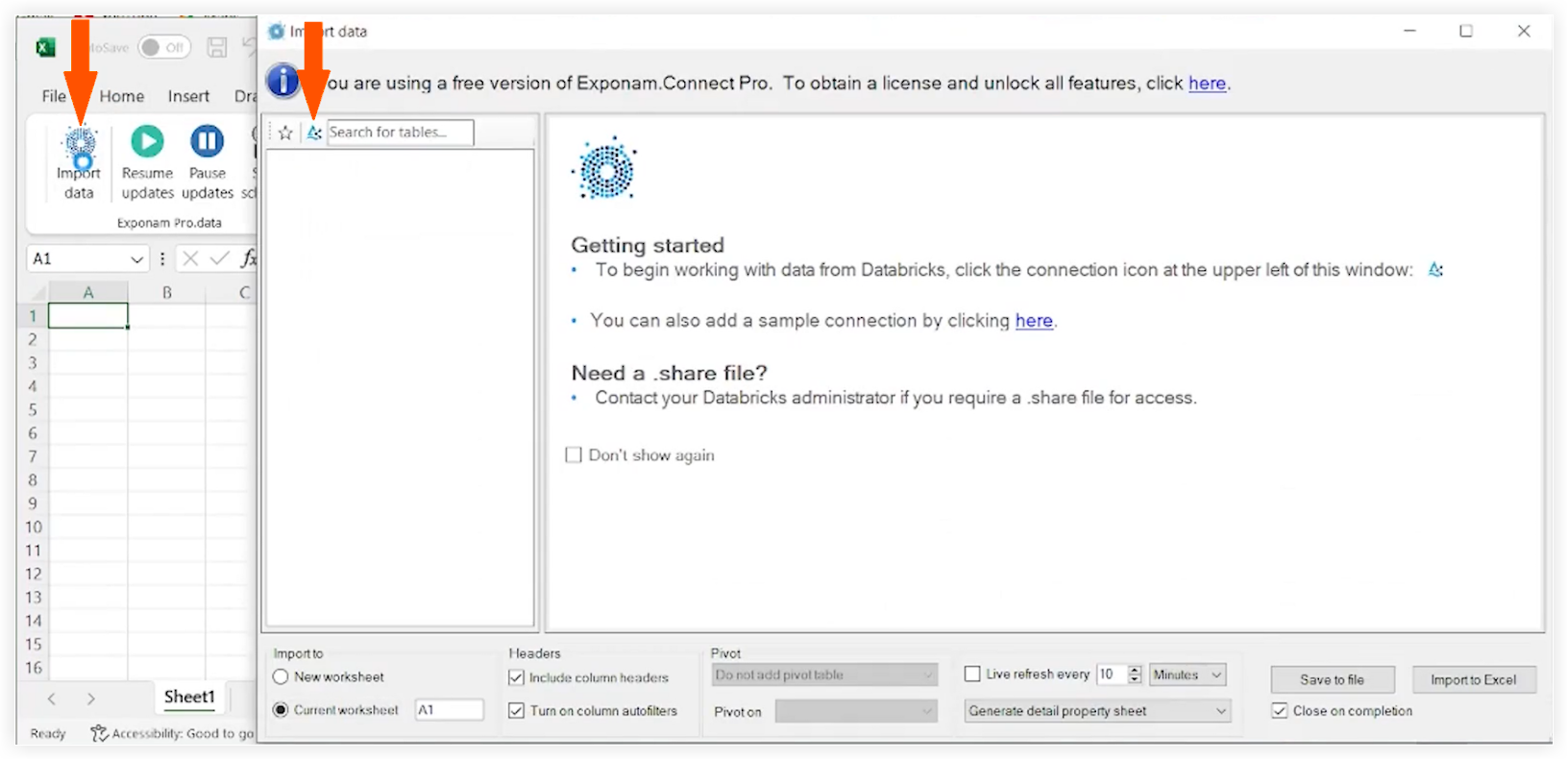
-
Localisez et sélectionnez votre fichier config.share.
-
Cliquez sur Ouvrir.
Sélectionner et filtrer les données
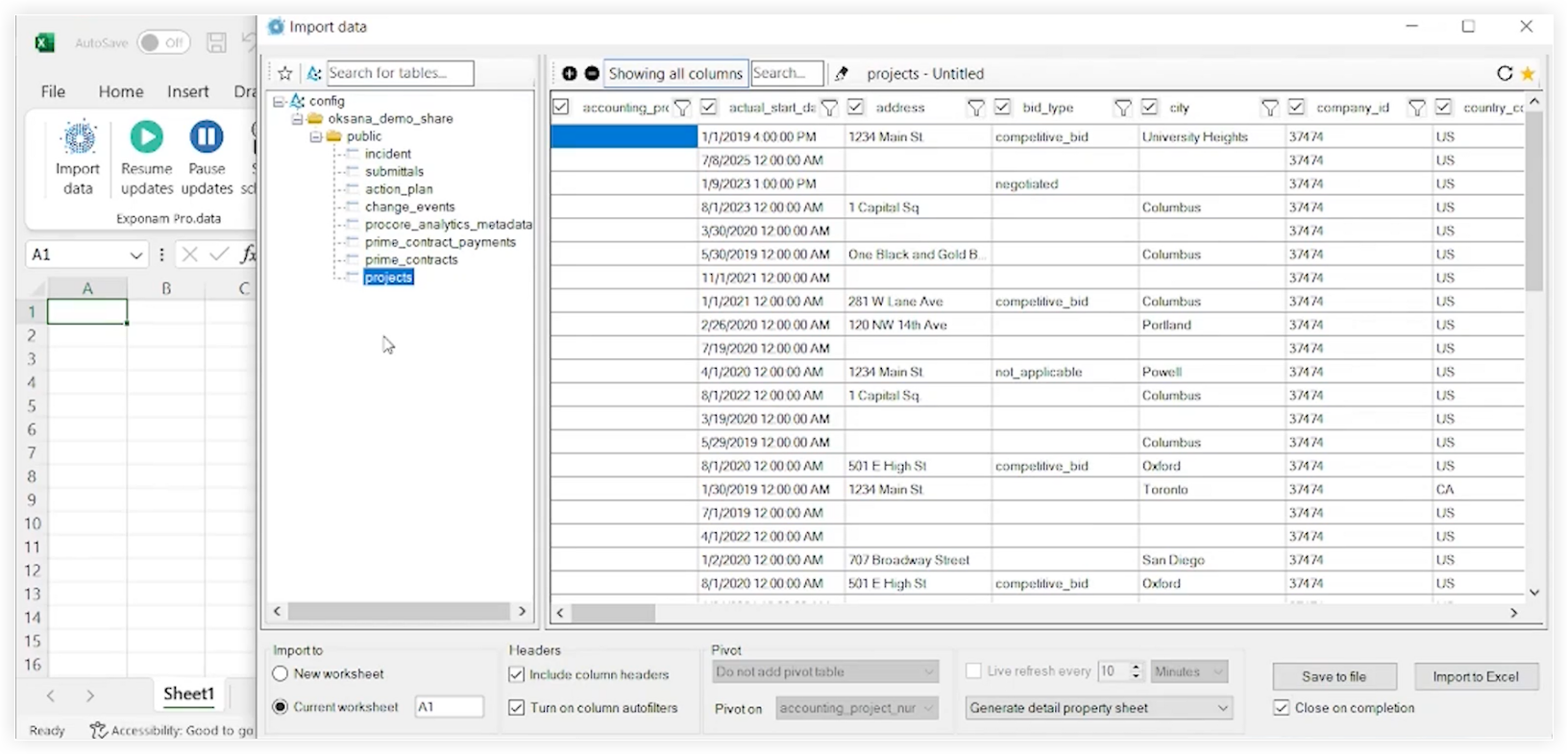
L’interface d’Exponam affichera désormais une liste de tous les tableaux de données disponibles.
-
Cliquez sur le nom du tableau auquel vous souhaitez accéder.
-
Utilisez l’interface Exponam pour affiner vos données avant de les importer dans Excel. Par exemple, vous pouvez appliquer des filtres, sélectionner des colonnes particulières, etc.
Importer vers Excel
-
Passez en revue votre configuration et le nombre de lignes.
Remarque : Assurez-vous que le nombre de lignes est dans la limite de votre licence. -
Cliquez sur Importer vers Excel.
Les données seront remplies dans votre feuille de calcul Excel active.
Vérification
-
Assurez-vous que les colonnes et les lignes d’Excel correspondent à ce que vous avez sélectionné dans la fenêtre Exponam.
-
Vérifiez que les types de données (dates, devise, etc.) sont correctement formatés.
Dépannage
-
Onglet « Exponam Pro » manquant. Assurez-vous que l’installation a réussi et vérifiez les paramètres « Modules complémentaires » d’Excel pour confirmer qu’elle est activée.
-
Erreur de connexion. Vérifiez que votre fichier config.share est toujours valide et que vous disposez d’une connexion Internet active.
-
Limite de lignes atteinte. Si seulement 100 lignes sont affichées, vérifiez l’état de votre licence dans les paramètres d’Exponam.